This is the 3rd of 3 challenges that I raised in my post “A semantic perspective on the challenges of analyzing human networks“
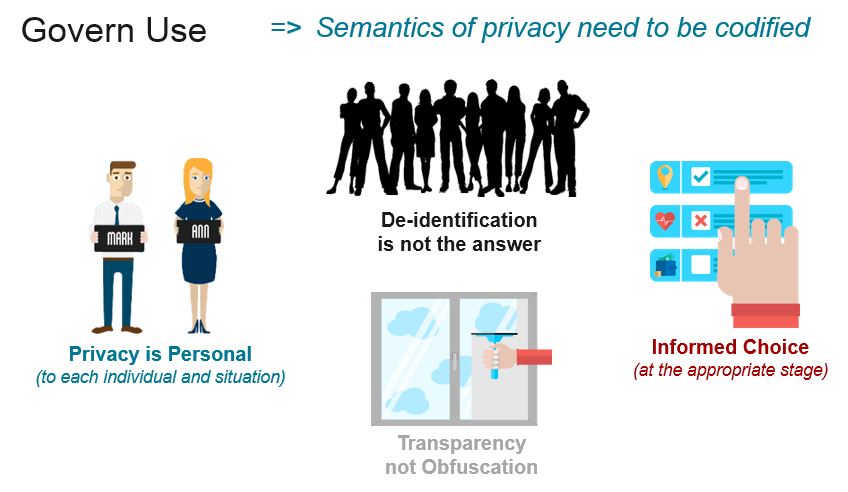
Privacy is a gnarly topic that divides people; this isn’t too surprising since privacy is personal and specific to each individual and each situation. I may be happy to share my driving history with my auto insurer but not my employer, or my food shopping history with my health provider but not my health insurer (unless there is an incentive to do so). Sometimes my privacy decisions are thoughtful and sometimes arbitrary, but they are always mine and personal to me.
These days the privacy discussion tends to degenerate into a shouting match between those perceived to be protecting mankind from exploitation and those that are out to exploit and manipulate. Clearly the situation isn’t that black & white and the rhetoric isn’t helping us move forward in a productive way. I personally believe that we are fighting a loosing battle in trying to prevent data from being shared; the Internet is just too porous and our use of social, mobile, and increasingly “connected devices” (the Internet of Things in technology parlance) is only exacerbating the situation. So if we can’t stop the flood of data, and in many cases it’s not in our interests to try, how do we control how it can be used? This is where I feel semantic technology can help.
Imagine that a privacy model existed, ratified by governments and privacy advocacy groups, that classified information (types of data, insight, facts, …), the ways it could be used, the types of people or organizations that could use it, the required privacy approval process, and allowed us to codify this, so that individuals could define their own privacy policy (in a very simple language) and applications could execute it on their behalf. Instead of organizations having a privacy policy that they force us to accept, individuals would have one. Data would still be changing hands, however it would only be (legally) used if the individual’s privacy model approved it.
If there was an identity eco-system where each individual controlled their own identity and the privacy policies around it, where information could be shared between people even if they didn’t know exactly who the other was, then you could “have your cake and eat it too”. Deidentification in certain cases and identification in others. Now this topic of an identity ecosystem is not a new idea (some links below), however even with such a system we would still need semantic models to facilitate definition of privacy policies; models that would allow individuals to simply describe in general terms (not a 25 page legal document) how they would like “data about them” used. Note that I don’t say “their data” since in many cases they may not own the data; perhaps a friend shared something on Twitter or an analytics engine generated something from deidentified sources. Which brings me to one of my favorite topics to argue about – deidentification; so I’m going to finish this post with a mini-rant on the topic :-)
Deidentification is the sledge hammer that is often suggested as the solution to all privacy evils despite it being the wrong answer for many reasons. I’m not arguing against deidentification as an important weapon to have in your privacy arsenal, but its only one of many and not even close to sufficient to address privacy in its entirety. I’ve many reasons for having this opinion, but most pertintent to this post is my belief that it sets the false expectations that the problem is solved once you deidentify any data you collect. This is fundamentally not the case. Firstly, analytics is making it increasingly easy to reverse engineer identity, so by setting deidentification at data collection as the minimum requirement, we’re effectively giving the green light for legally circumventing privacy. Data collection isn’t our issue, data use is. Secondly, in many cases deidentification at source isn’t really in the interest of the individual. For example; take clinical research, this is an area where its in all our interests to share our health data, its also an example of where you don’t actually want your data deidentified at source (which is what tends to happen). Why? Because while you do want your privacy respected, in certain cases, such as if it turns out that the analysis discovers you are at high risk of a certain disease, then you may want the option to be informed. Your privacy policy may state that under certain conditions you are happy for you to be contacted. If your data is totally deidentified at source then this is never an option. And there are many trivial (non-life saving) examples of this; perhaps you want a trusted retailer to notify you about a product on sale, an insurance company telling you about a new policy more suited to your lifestyle choices, or an employer giving you feedback on an satisfaction survey you completed some months ago. There is no technical reason why data needs to be deidentified as long as there was a trusted identity ecosystem and codified privacy policies.
- Challenge 1: Graph Modelling & Construction
- Challenge 2: Opening a Graph for Business
- Challenge 3: Effectively Governing Use
Below are a smattering of links to studies, programs, and opinions around identity ecosystem. Some I agree with, others I don’t, but all of them ask interesting questions which need to be asked and answered over the coming years.

Leave a comment